Hi Folks,
This post is about Dataverse and Git Integration which is the most sought after feature in the todays automation Era. This is a preview feature, you would need to create a new environment with Early Access enabled to test this feature or you can use an existing US Preview environment for testing this out.
While every MDA(Model Driven Application) and it’s components can be safely and moved across the environments using Solutions with the help of Azure DevOps Pipelines. However when coming to integrating Power Platform Solutions to Azure DevOps, we had to manually export the solution and download them each and every time when we would like to commit the Solution Artifacts to Azure DevOps Repo.
With this new Preview feature we can directly integrate the Power Platform Solutions to Azure DevOps.
Let’s see this action…wait a moment, there were some prerequisites to be considered…
- Environment should be a Managed Environment to start using this and you need to be an Admin for the environment
- Azure DevOps subscription and license should be available to set this up, also permission to read source files and commits(should be a member of contributor group in Azure DevOps) from a Repo
- Your email address used for Azure DevOps and Power Platform Solutions should be the same
Setup:
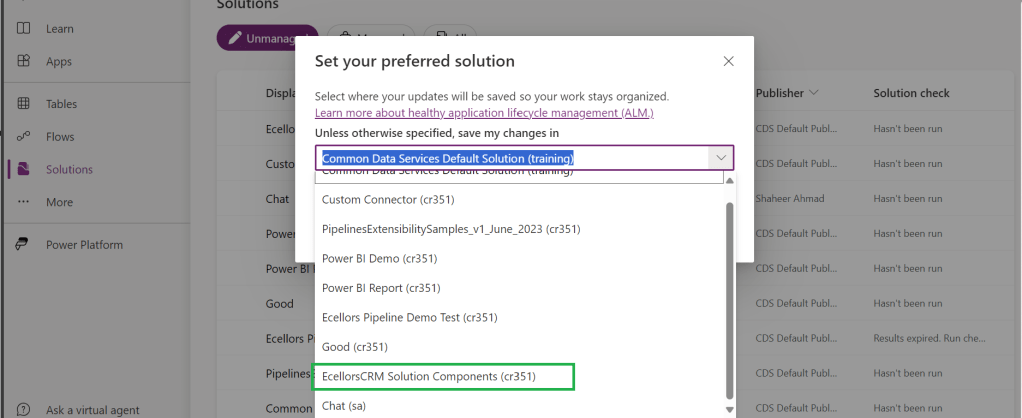
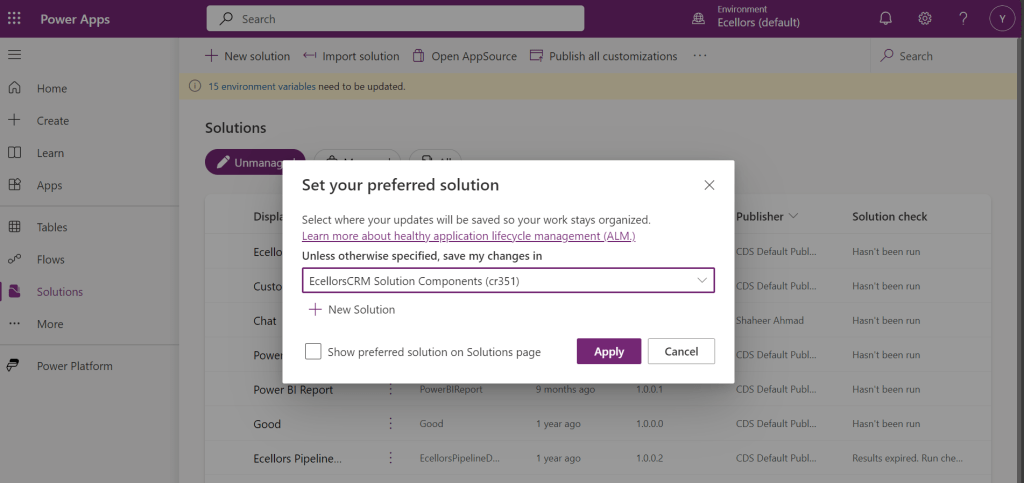
Connecting Dataverse with Azure DevOps is easy but requires a bit of understanding of the Binding options available.
Well, there were two types of Binding options
- Environment Binding – Single root folder binds to all the unmanaged solutions in the environment
- Solution Binding – Different solutions uses a different root folder in Azure DevOps for binding
Note: Once the binding is setup, there isn’t away to change, so set this up carefully, else you may need to delete the folder and create a new one in Azure DevOps.
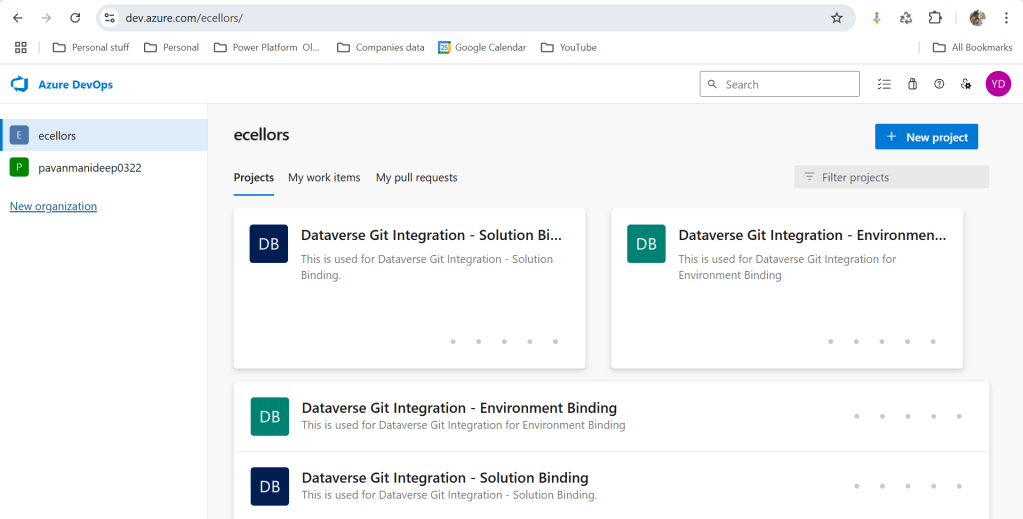
Let’s see one by one…for demoing purpose, I have created two projects in Azure DevOps Instance
- Solution Binding: When we use this, all the components will be available as pending changes
- Environment Binding: When we use this, all the unmanaged solution components will be mapped to one Azure DevOps root folder. Let’s set this up.
We are currently able to use only Solution binding, as Environment Binding doesn’t show up any changes to be committed, but there is a catch here.
We can set up for Environment binding and verify if the Solution components are getting marked as pending changes or not. Do note that Setting up the Binding is a one time activity for environment, once setup, it can’t be changed from one type to another.
Open https://make.powerapps.com and navigate to solutions and click on ellipses as below
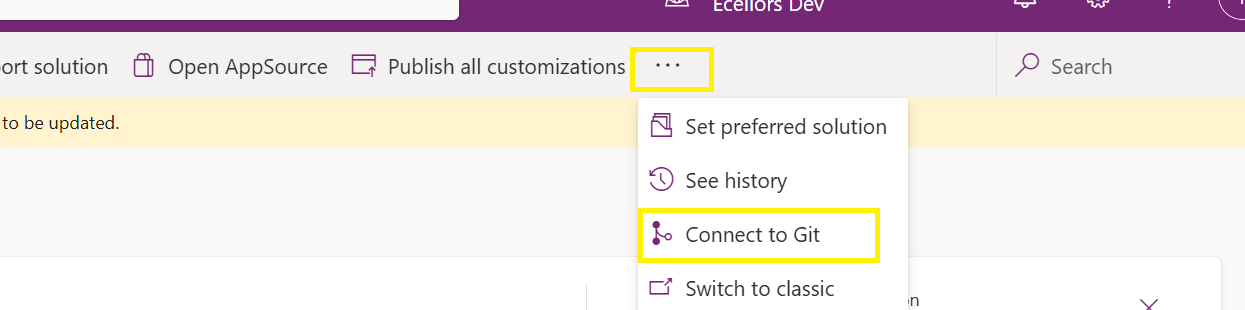
Once clicked on Connect to Git
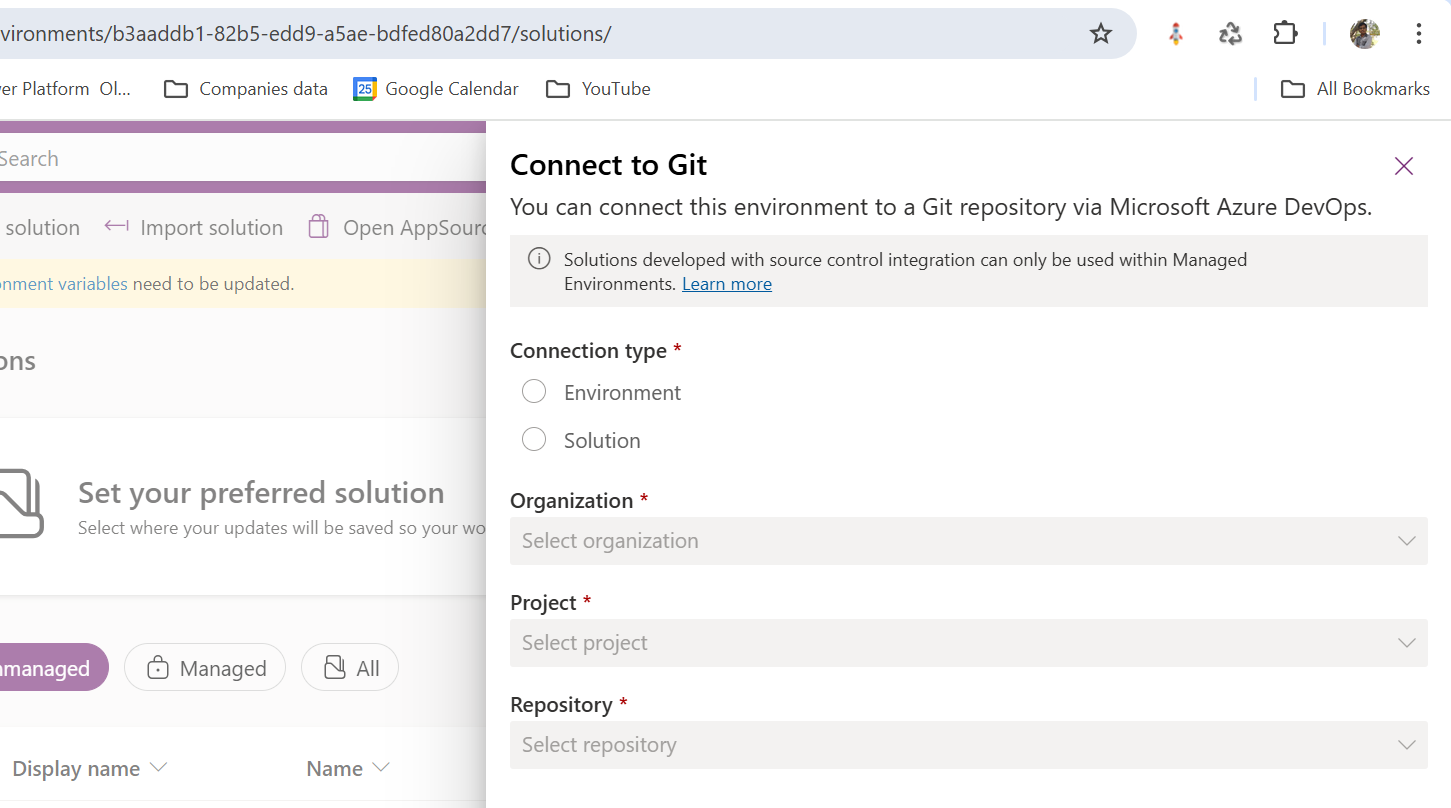
Since we were currently using Environment binding, let’s select the Connection Type as Environment
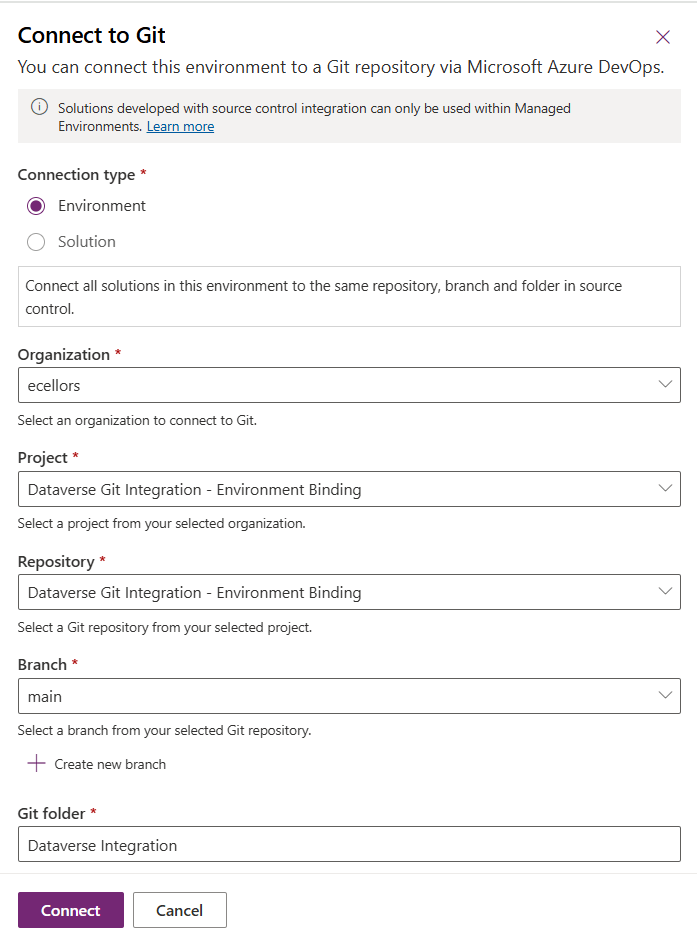
Then click on Connect, once connected, you should a alert message in power apps maker portal at the top.

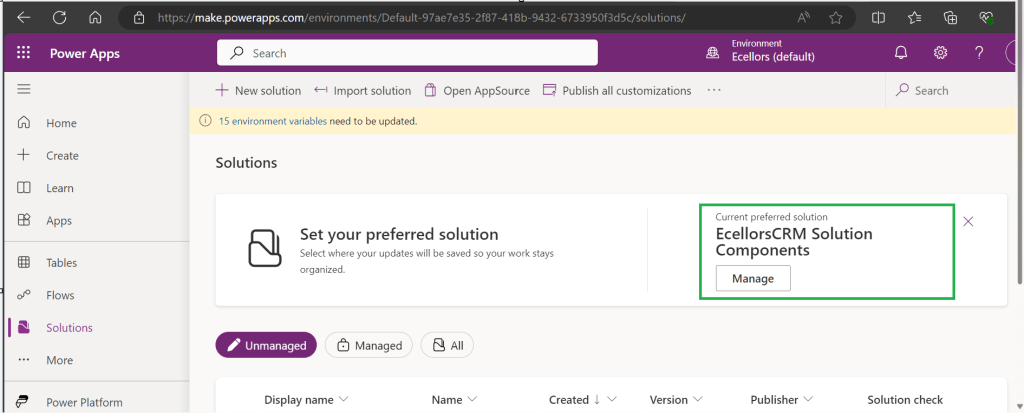
Now create a new solution as below named ecellors Solution
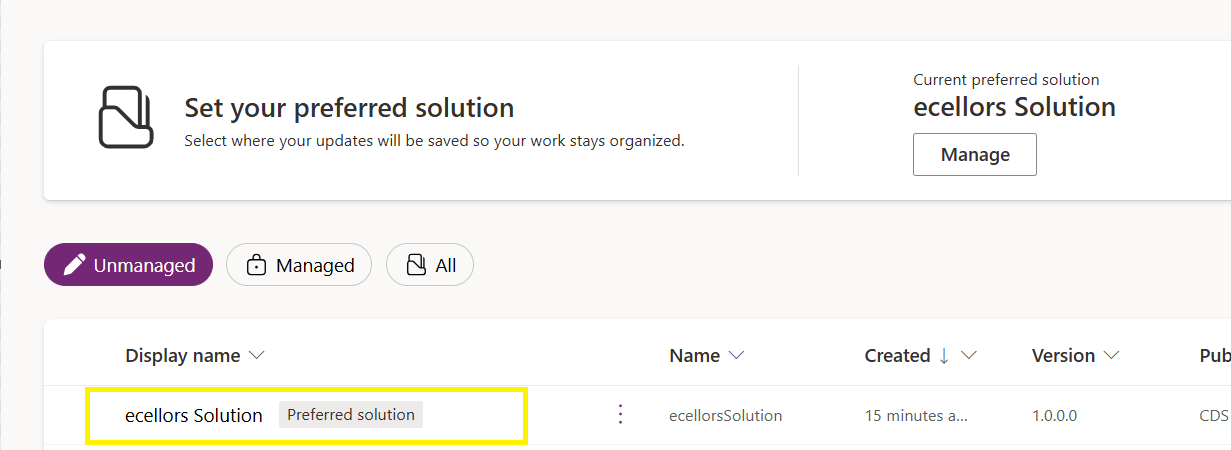
Verify the integration by clicking on Git Integration as below
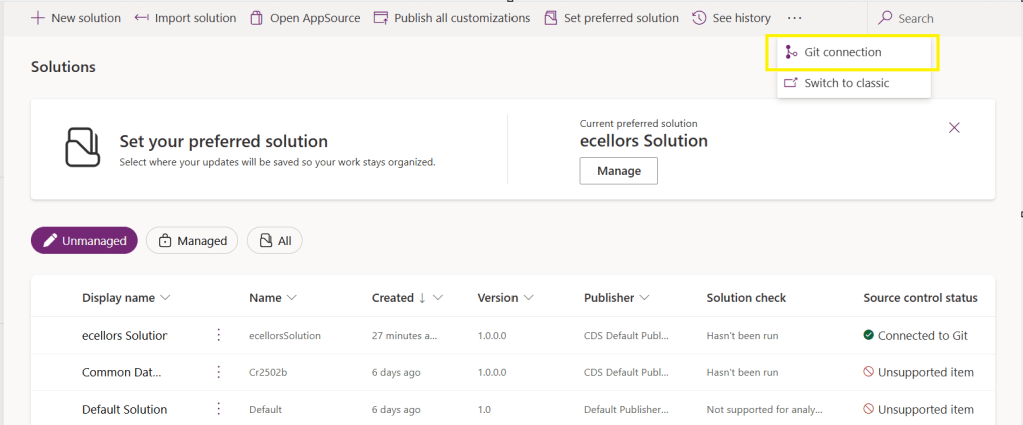
It should show as below

Now let’s add few components to the solution we created
Once added, let’s publish the unmanaged solution and verify it..
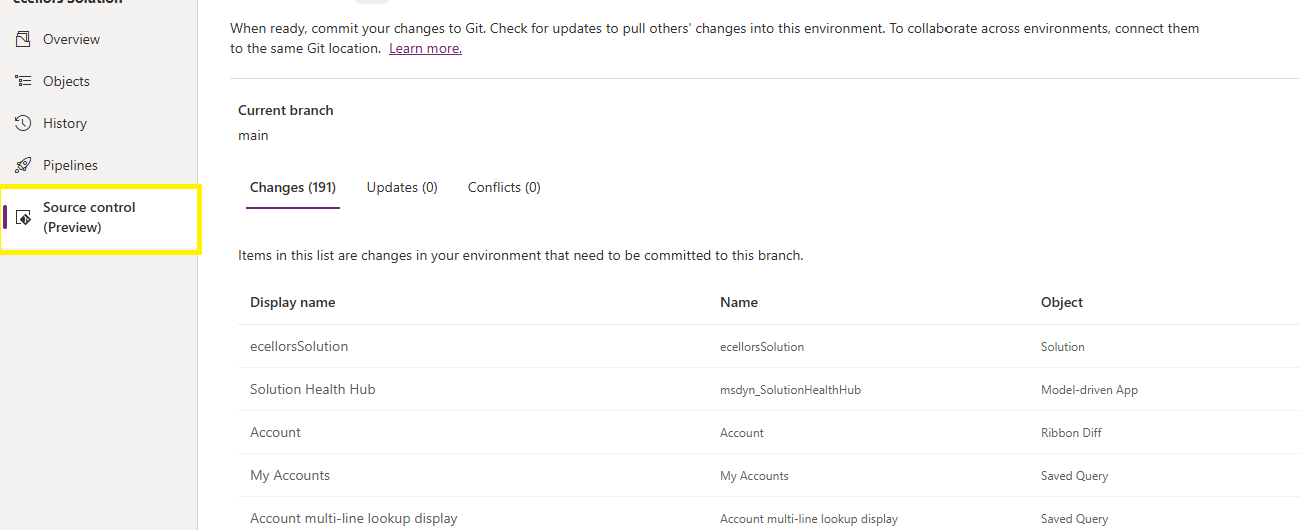
Do look closely, you should see a Source Control icon highlighted in yellow color for illustration.
Also, you should see a commit option available at the top
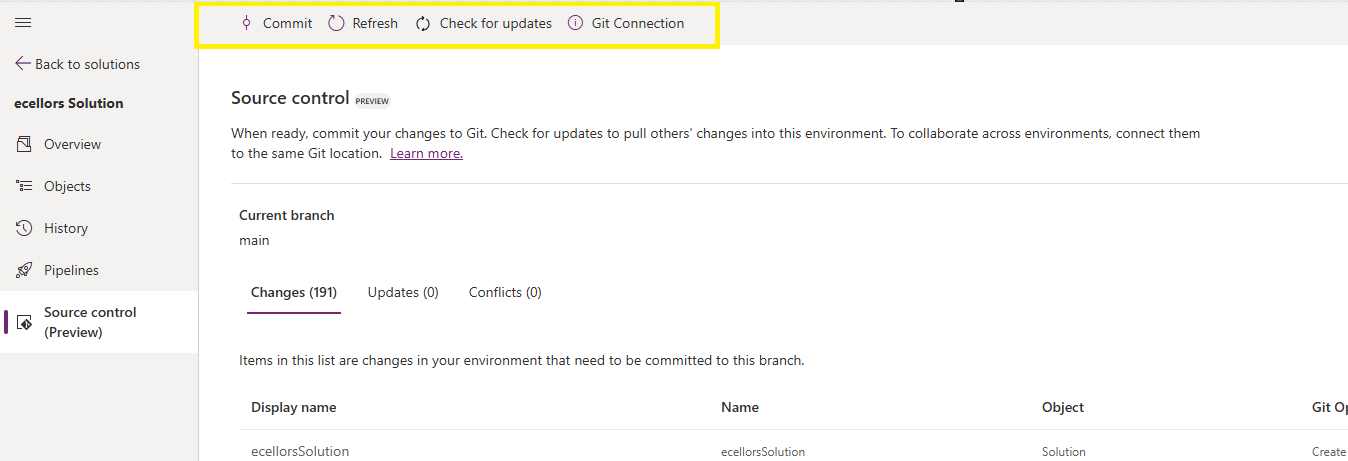
You should now be able to commit the solution components as if you are committing the code changes.
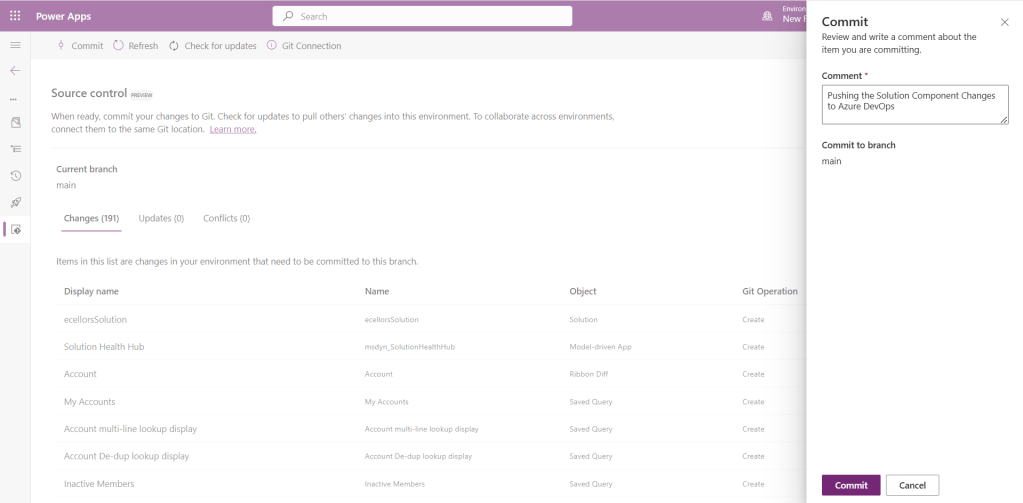
It also specifies the branch to which we were commiting…
While it takes few minutes unlike pushing the code to Azure DevOps to push the changes, however this would depend based on the number of solution components you were pushing..once it is done, it will show a commit message like below…
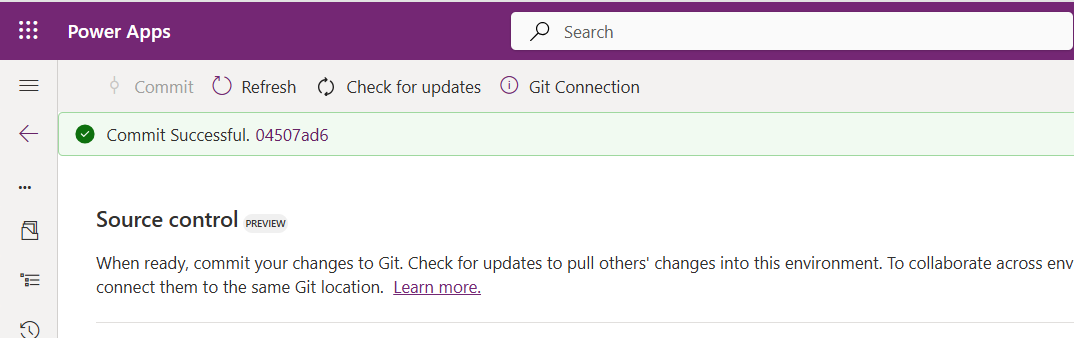
Now let’s verify our Azure DevOps Repo..for this you can go back to the main solutions page, click on Git Connection at the top..
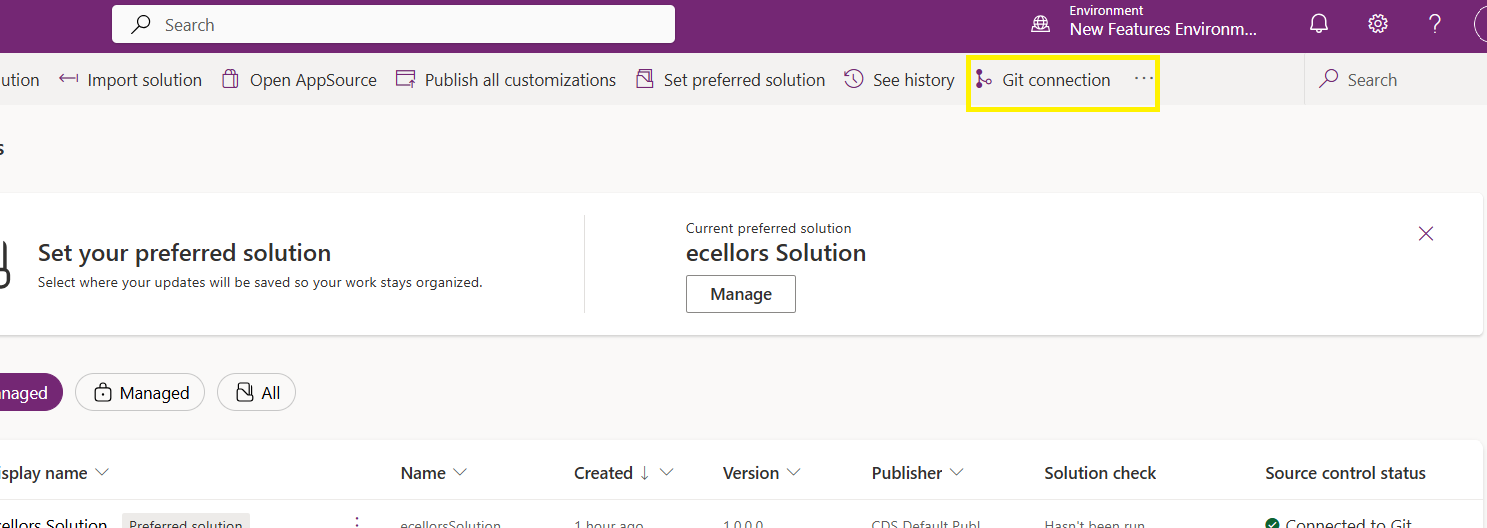
After clicking on Git Connection, click on the link to Microsoft Azure DevOps as below
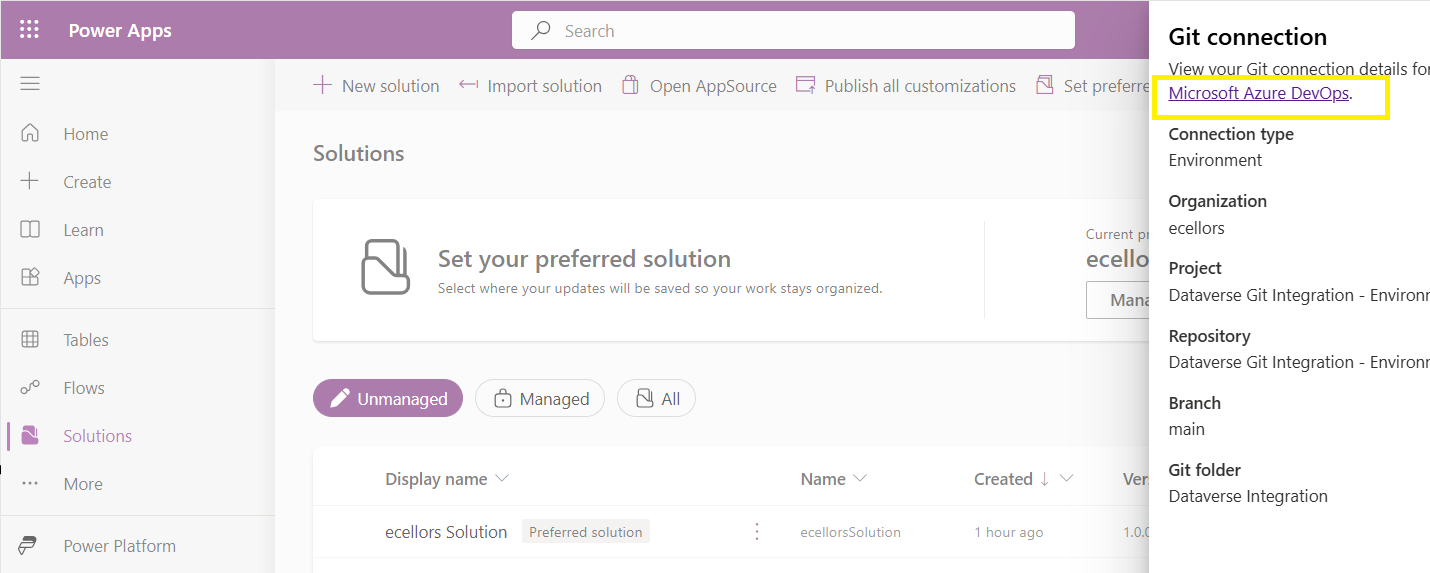
Then you should be navigated to Azure DevOps folder as below where all the solution files will be tracked component wise.
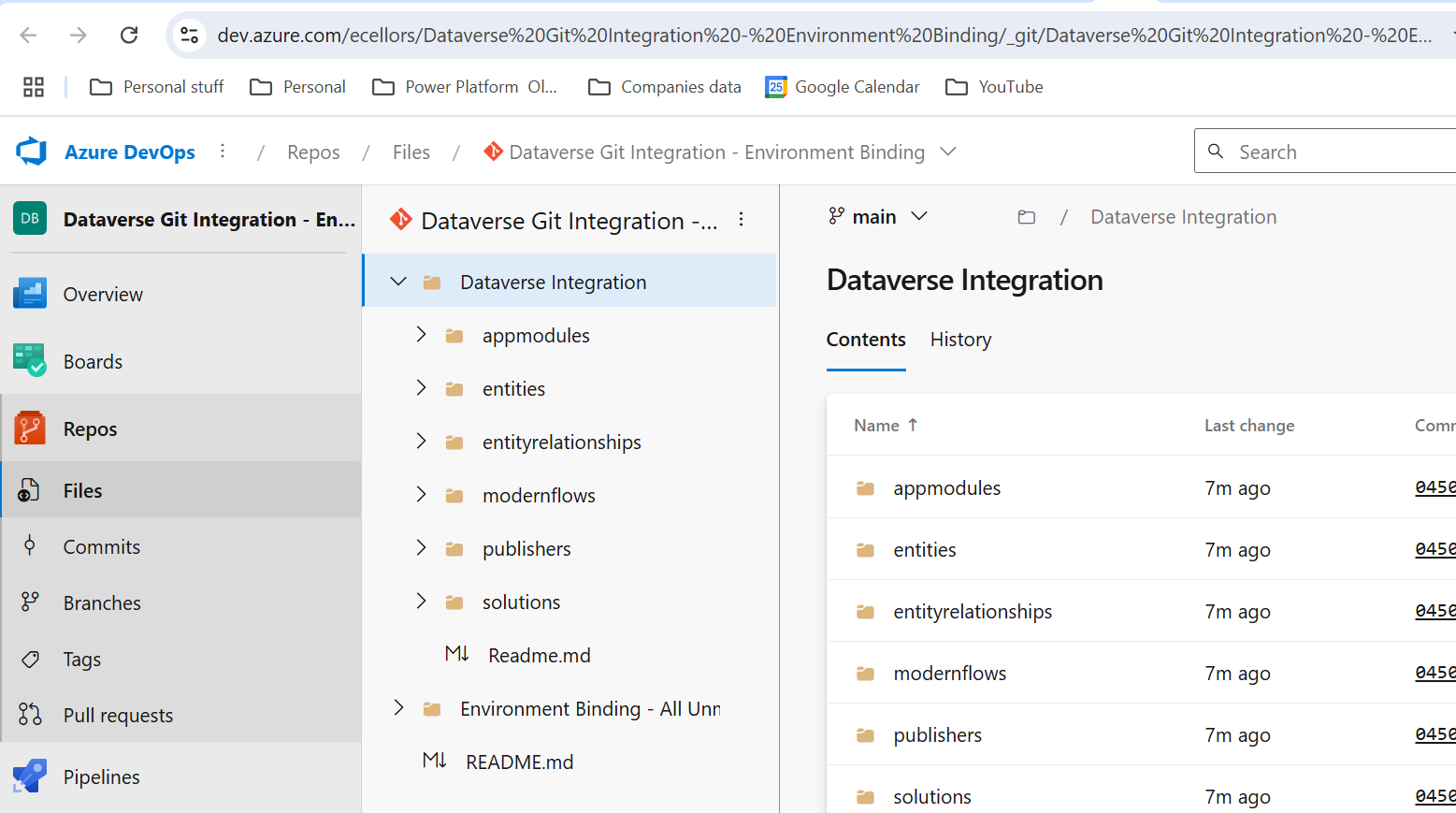
Now we will move back to Power Apps maker portal and make some changes to any of the components inside the solution…
Let’s say, I just edited the flow name and created a new connection reference, saved and published the customizations.
If you did some changes at the Azure DevOps repo level, you can come back and click on Check for updates, if there were any conflicts between changes done in Azure DevOps and component in solution, it will be shown as conflict.
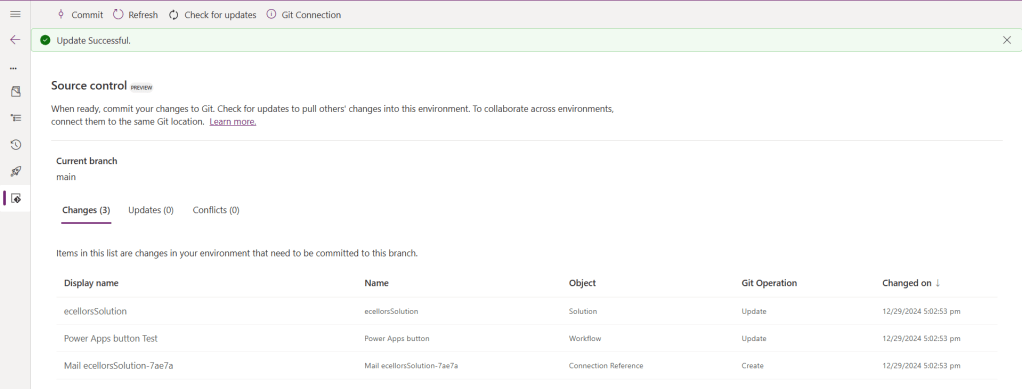
We now have 3 component changes and all were listed here…you can click on Commit.
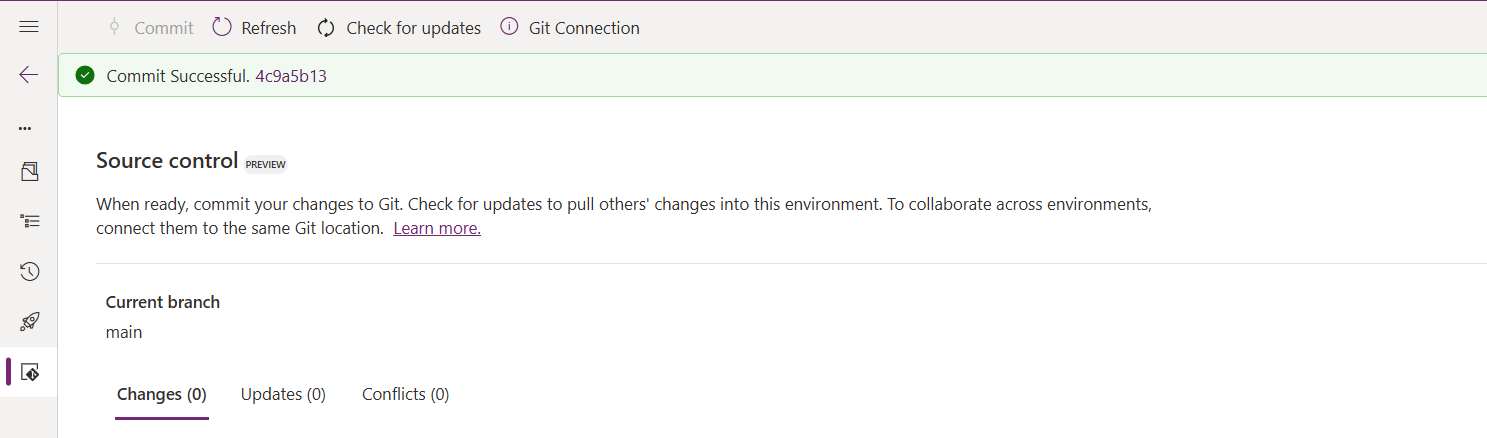
As soon as the changes are committed, you should see a message saying Commit Successful and 0 Changes, 0 Updates, 0 Conflicts.
Now you successfully integrated Dataverse Solution components with Azure DevOps without any manual intervention required while deploying solutions using Azure DevOps Pipelines.
Hope you learned something new today…while feature is still in Preview and only available for early release, while couple of issues still need to fixed by Microsoft.
I have tested this feature by creating an environment in US Preview region and this feature will be a good value to projects using Automation and this solution repository can be further deployed to other environments using Azure DevOps Pipelines.
This will be rolled out soon next year, hope you learned something new today…
Cheers,
PMDY